Pymma (www.pymma.com) is one the OpenESB project leaders (www.open-esb.net) and continuously works on OpenESB improvements and new features to offer the best Extended Service Bus on the market. Our Extended Service Bus covers a very large scope of applications from Internet of Thing, Integration of Services, Domain-Drive Design to Streaming Application or Event Processing.
One of the main OpenESB features is the orchestration of services based on a powerful BPEL engine. OpenESB BPEL engine generates a large amount of information about the running processes, useful for process analysis. Further to our customers' requests, we recently improved the BPEL engine to easily extract the information available during the process executions. Once our improvement completed, we evaluated that some of our customers could generate tens of billions of messages every day on their multi instances production systems.
OpenESB has not been designed to aggregate and analyse such amount of data. So, our architects decided not to rely on OpenESB to gather and analyse the messages coming from our orchestration system, but on an external application designed for this purpose.
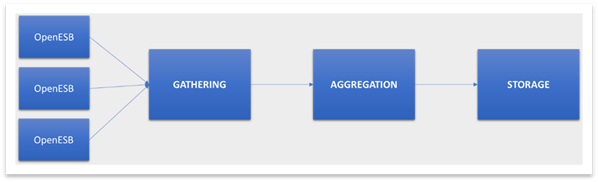
This tiers application must fulfil four main requirements: ingest the flow of messages, put them together in only one place, aggregate the messages for further analysis then store the result of this aggregation on a persistence system queryable with a SQL like language.
Ingestion and Gathering: OpenESB scalability relies on multiple instances running together. On production, it is common to see tens of OpenESB instances concurrently generating hundreds of thousands of events per second. These messages must be ingested and put together in a persistence system.
Aggregation: Our aggregation written in Java is defined in few steps (4-5 steps).
Storage: The final state of our process is stored in a persistence system and then used for statistic and dashboard purposes.
Due the amount of message issued by the OpenESB instances, we were worried about message ingestion and aggregation scalability. Our first approach was to focus our efforts on the most known Big Data products. We chose Kafka (https://kafka.apache.org) for ingesting and gathering the messages and Storm (http://storm.apache.org) to process the aggregation. We also tested Spark (https://spark.apache.org) but did not find its micro batch orientation accurate with our case. Another requirement was to get a storage system to store the results of our aggregations that provides a SQL "like" language to query it. Once again, we chose a solid value in the Big Data world and select MongoDB.
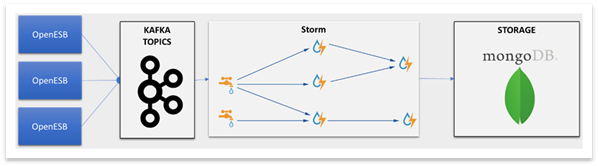
So, we select a set of three nice products and then developed, deployed our application with very good results. We were especially impressed by Strom capability, reliability and scalability.
Some of our customers were volunteers to be beta testers and started to install our solution. We provide them with the deployment scripts, the tools settings and the application code. We noticed that our customers were not interested by a virtual machine we prepare for them, but to master the deployment in production, they wanted to install themselves this set of products.
Quickly, we got negative feedbacks from our customers. The main concern they expressed was on the number of tools to master and install, since, additionally to the three products, ZooKeeper must be added to use Kafka and Storm.
Even if our solution was powerful and scalable, we understood that it would not get our customers' acceptance, because, the time and resources to set it up in many environments did not match the investment and budget planned by our customers on that topic.
So, we asked our architects to re-think about another technical solution that could support our first requirements with a prompt and easy deployment. They started searching for a reliable product that could provide a high-speed injection like Kafka, scalable processing like Storm and a generic storage with a query language such as MongoDB.
After evaluating some products on the market, we thought that the opensource product Apache Geode (http://geode.apache.org) could be a good candidate. Geode is a distributed cache with a powerful infrastructure to process events and messages. Geode is the inheritor of Gemfire (https://pivotal.io/pivotal-gemfire) products that started in 90's.
Geode/Gemfire is well known for its high-speed ingestion and can easily manage streams with hundreds of thousands of messages every second. This feature allowed us to connect each OpenESB instance on the distributed cache and then store all the event in one logical place.
Each time a message is inserted, upgrade, delete in the cache, Geode generates events that could be processed synchronously or asynchronously by event handlers. We used these handlers to implements process steps. When a handler is complete, the result of the process is put back in the cache and new events are generated.
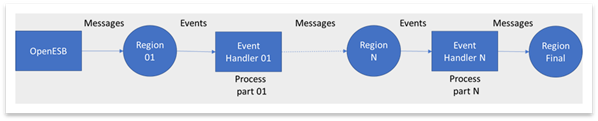
So, we implemented our processes in a similar way than the previous version with Storm. We used Geode Asynchronous Event Queues and Event Handlers to "replace" the bolt used in Storm. The parallelization of our aggregation with a great scalability provided by storm was easily retrieved with Geode.
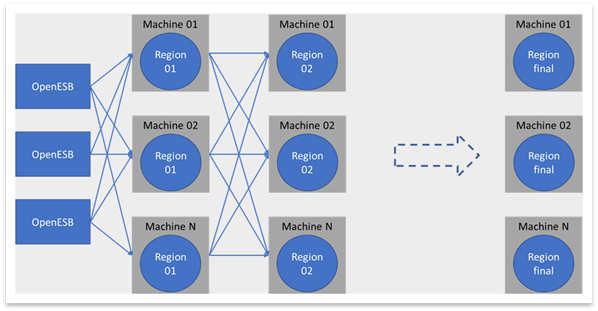
So, we replaced Kafka and Storm in our use case. Moreover, the need to install and set ZooKeeper disappeared as well. We also stored the aggregation results and queried Geode with Geode's OQL which is a SQL like language.
With the resources allocated to our benchmarks and our knowledge on the products, we got the same range of performances (nevertheless better with geode). But the main benefit when using Geode is the installation simplicity if you compare it with the trio ZooKeeper, Kafka and Storm.
In our use case, Geode simplify dramatically the deployment of our tiers application.
Drawback: Since some of our customers want to store the aggregation result "for ever", it is illusory to ask our customers to store "for ever" this information with Geode in memory. So in that case, an additional persistence system must be added to Geode and the Aggregation results must be saved in another persistence system for long term requests.
We wanted to replace Kafka-Storm-MongoDB with Geode, but as far as we understand how to use Geode today, a persistence system is still required and we suggest our customers to the couple Geode-MongoDB.
Nevertheless, for our application, we found in Geode a very nice solution to replace ZooKeeper-Kafka-Storm. Companies use many persistence systems and are less reluctant to share them with tiers applications and installed our aggregation system.
Conclusion: We added a data analysis application to OpenESB that requires high level performances. Our first idea relied on classical and well known big data software. Our customers found these tools difficult to understand, install and manage especially in a multi instances environment. This difficulty stopped our customers using our aggregation and analysis system. We redesigned our solution with Apache Geode which in our use case, replaced perfectly ZooKeeper-Kafka-Storm with a very simple deployment process.
At the high-level architecture, Geode is a "two plans product": one for the process (or the Services) and the second for the data. Both plans are deployed simultaneously and communicate natively with a great efficiency and scalability.
With this unique feature, for our use case, Geode supersedes tools such as Kafka, Strom or Spark and become our first choice for our analytic solution.